Post 27 -by Gautam Shah
.
Data is raw collection of facts. Data is categorized into sets by the class of its contents, such as the character, text, words, numbers, images, etc., and by the interconnections of the substance. These two are the factors that colour the data, which otherwise is neat collection of facts. Data must be further organized, structured, interpreted, and presented to be meaningful as information. Same data can be had by many people or agencies, but the way it is used it begins to be proprietary information. Data gains context during processing. Raw data is useless, and has no value except the cost of identification, collection and storage. Data once collected is preserved, as the same data may offer new vision or information in future.

In nominal usage, data refers to facts, posed to our receptive faculties or sense organs. Data is perceived, when it is within the limited perceptive (sensory) capabilities, and if has some relevance to our needs. Data perception is affected by the mental and physical state. Our mind (and other organs) processes the data into Information. Data processing refers to acts like gathering, manipulating and transmitting for specific objectives.

Data is open knowledge, but when perceived in some context or for a probable purpose, it becomes information. Information, on the contrary is a personalized property. One person’s information becomes another person’s data. To work efficiently, and within the personal biological capacity, one retains only relevant sections of data.
Data can be processed manually, mechanically and electronically. And with each of the processing data gets structured differently providing new insights. A machine (mechanical, electronics) processes data according to set parameters, so is more objective then any manual processing.

Electronic or digital systems have better receptors and larger storage capacities (and improving day by day). Such systems, like their biological counterparts, invariably include barriers or filters to select only relevant things. A computer during the receiving and recording phase converts relevant things into a storable representation or a surrogate form.
The information stored in the mind thins out with time, so must be either communicated or recorded. Recording is formatting information over a medium. In-forming implies that a form is impressed onto -a medium. The formatted (recorded) expression on a medium is less likely to get lost with time. Recorded and communicated material is already processed, but as we re-communicate it, it gets further processed. During each process of expression, perception, recording or retrieving, information corruption occurs.
Methods and modes of ‘formatting’ the information are like: writing, printing, transmitting, receiving, storing, retrieving, etc. However, formatting, ‘conditions’ the data, and often ‘corrupts’ it. The forming mediums are physical, such as: paper, magnetic tape, etc. and formatting tools are: languages, images, graphics, metaphors, etc.

The information expression and formation (on a medium), both are acts of communication. The originator, though, has less control on how the expression will be perceived or recorded (in-formed). The Information originator accessing own records at some other time-space level cannot revert to the original physical and mental state, and so re-experience or reestablish the original. The communicated information manifests slightly differently, yet it is a ‘knowledge transmission process’. For communication to occur the originator and the accessing user both must follow common modalities.
Documents are ‘lots of related knowledge’, which when referred to, provide the intended information. Once information is perceived from data set, it is placed or linked to a document. In other words like other storable units it is modulated according to what it is to contain, and stacked (stored) according to how it is placed, referred and retrieved.

Traditional documents are like: letters, reports drawings, specifications, procedures, instructions, records, purchase orders, invoices, process control charts, graphs, pictures, etc. Such documents’ ‘pages’, chapters or sections are placed together to maintain order of placement. Sub units of documents also carry a positional identifier like page, chapter or section number. Documents are stored in their order of arrival, category, size, nature (paper, books, tapes, etc.), author etc. Traditional documents as sequential data storage system are also created in the form of index cards, punched data cards, magnetic tapes, etc. A digital document stores information in pre-sized lots of bytes and bits. These may offer random access, such as with floppy disks, CDs, HDs, etc. A file allocation table FAT as a dynamic index system manages the access to it.

Files are the most common units of information transfer. Filed information has: a title, a description of contents and the mass of content. Additionally it occupies a space, so size, and the birth context (date/ time/ location/ other circumstances of origin). Beyond these primary endowments, a file may be given different attachments (links and references). A file carries many identifiers such as:
- time (of origin)
- size (of storage, transmission time & effort)
- author, contributors
- content (index, key words, summary)
- place of origin
- place of destination, identity recipient
- authority to create, read, write, alter and delete the contents of a file
- affiliations, linked documents, preceding and following documents
- references
- embedded codes
- signs, symbols
- language
- style
- mode of communication
- limits and conditions of relevance
It is through such identities that a file begins to be relevant or worthy of access. A simple file is nominally static, because its data entities are allocated specific physical space. A complex file may contain variable size space allocations. There are often filters that decide which of the data entities are to be allocated a free or variable space.

Data entities in a file remain permanent or are changeable. The conditions that cause a data to remain permanent or be variable could be external or internal. The internal conditioners are inseparable parts of information files. In a static file, the structure remains unaltered even while data entities are changed. The meaning deriving out of that file however, may change. Static files are easy to process, but are incapable of providing qualitative information. Static files usually contain data that is mathematical or substantially logical. In dynamic files the structure of a file gets altered along with the nature of data entities. Dynamic files are complex to process.

Hard copy vs Soft copy: Substantial quantity of information is generated as hard copy, i.e. written or printed. It is possible to copy these type of documents in parts or whole, through processes like carbon copying, scanning, lithography, screen printing, transfer printing, photo and Xerox copying. Some of these processes require specific media. Few processes are capable of enlarging or reducing the scale (micro films). But contents cannot be edited, revised or manipulated. A digital data file is often called a soft copy because its contents can be manipulated with much ease. It can also be linked as a whole or by its parts, to other files or their parts. It can be analyzed, dissected, reassembled, rearranged or restructured. Through such manipulations even ordinary looking data takes on different forms, and new meanings can be established.

Most printed documents are opaque. It is very difficult to superimpose or merge two or more such documents. Digital documents, on the other hand can be treated as set of layers or even three dimensional matrices. Digital documents can be treated as transparent and miscible. Auto-CAD creates files as transparent layers. Digital files could be made interactive (such as with spreadsheets), i.e. a change in one file can be made pervasive in all other linked files.
Information Resources of Organizations: Data arrives in organizations, at periodic intervals or on a continuous basis, but it arrives in parts, that will:
- – probably form a whole,
- – automatically create a structure with definite boundaries (close ended)
- – form an ever growing matrix (open ended).
Organizations receive and generate lot of data, which have two sets of relevance. Information with distant use is strategic, and will be used for planning and forecasting. Strategic information is more general than any tactical information. Information with immediate use is tactical, and is used for decision making and problem solving. Operational uses of information are very occasion or situation specific.

Prime Internal Information Resources, IIR for organizations are: experience and knowledge that comes with owners, employees, consultants, etc., and data generated from the routine activities. The External Information Resources, EIR are: input and feedback from consultants, suppliers, contractors and clients. These are media-based such as books, periodicals, internet, CDs, tapes, etc. External information once procured by the organization, if properly stored can be a great internal asset.

Internal information is personal, departmental or organizational. Internal information resources are nearly free, require only processing at a negligible cost, but are ignored. Organizations thrive and proliferate on the quality and quantity of data within their reach. Organizations by continuously processing their data generate synergies that in turn sharpen their data processing capacity.
External information is inter-organizational, fraternity level, society, community, national, or of a universal domain. External information is acquired for a payment of compensation in proportion to its quality, quantity and acuteness of need. Organizations, as a result, end up paying a stiff price for sourcing external information.

Cost of information: Information as a commodity can have an ordinary cost, if it is universally available and not urgently needed. However, information of rare or proprietary nature and that requiring immediate access can have a high price. Information is also available without any obligations in many free domains. Cost of information is also formed by absolute factors like the cost of acquisition, processing, storing, retrieval and transmission.
Information systems and emerging forms of business organizations: Information systems affect the structure of organizations and design of the workplaces. Information networked organization are more dynamic because the workers communicate among themselves, and with other firms. These provide for greater coordination and collaboration in projects’ handling. These strategies have also ‘led many organizations to concentrate on their core competencies and to out-source other parts of work to specialized companies’. ‘The capacity to communicate information efficiently within an organization has also led to the deployment of flatter organizational structures with fewer hierarchical layers’.
Organizations with clustered information systems are built around portable computers, mobile telecommunications, and group-wares have enabled employees to work virtually anywhere. ‘Work is the thing you do, not the place you go to’. Employees who work in virtual workplaces outside their company’s premises are known as Tele-commuters.
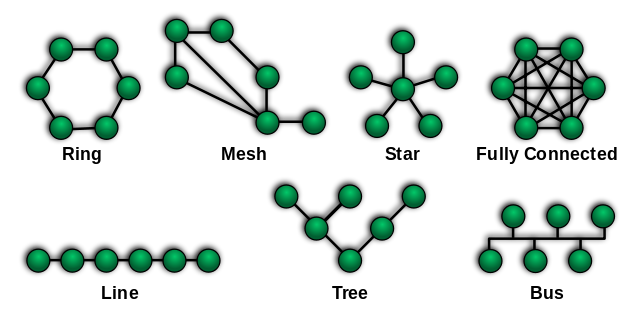
Two forms of virtual organizations have emerged: network organizations and cluster organizations. A network organization of individuals or geographically widely dispersed small companies working with internet and wide area networks, can join seamlessly through specific protocols to present a multi disciplinary appearance of a large organization. The subsets operating in all time zones seem to be operating 24 x 7. In a cluster organization, the principal work units are permanent, complimented by multiplicity of service providers or temporary teams of individuals. A job or project begins to percolate within the cluster and different sub units begin to react to it, providing their inputs. A solution begins to emerge from apparently fuzzy and often unrelated ideas or concepts. Team members, are connected by intranets and groupware.
‘Data is abundant, but mostly redundant. Information exists in data, if one is inclined to derive knowledge out of it. But for wisdom one may not need any knowledge’.
Knowledge is acquisition involving complex cognitive processes, such as perception, communication, and reasoning. Knowledge is a familiarity, awareness or understanding of someone or something, such as facts, information, descriptions, or skills. These are acquired through experience or education by perceiving, discovering, or learning. Knowledge can be implicit (as with practical skill or expertise), or explicit (as with the theoretical understanding of a subject).
Knowledge is learning from experience, observation and perception. The learning from information resources is an ever evolving process. Observation and perception are subjective, but information resources offer verifiable opportunity. The information resources offer simultaneously several points of views, strategies and solutions.

Application of Artificial Neural Networks : Most of the traditional processes, including the computer programmes are linear or sequential. Execution occurs in a step by step process and sometimes with circular commands that use iteration. A neural network processes information collectively, in parallel mode. It changes its internal structure based on the information flowing through it. It is a complex but adaptive system.

Artificial neural networks are applied to speech recognition, image analysis and adaptive control, to construct software design tools and autonomous robots. Most of the currently employed artificial neural networks for artificial intelligence are based on statistical estimation, optimization and control theory. Application areas for Artificial Neural Networks also include system identification and control (vehicle control, process control), game-playing and decision making (backgammon, chess, racing), pattern recognition (radar systems, face identification, object recognition and more), sequences recognition (gesture, speech, handwritten text recognition), medical diagnosis, financial applications, data mining, visualization and e-mail spam filtering.
Artificial neural networks are applied to following categories of tasks:
- Function approximation, or regression analysis, including time series prediction and modelling;
- Classification including pattern and sequence recognition, novelty detection and sequential decision making;
- Data processing, including filtering, clustering, blind signal separation and compression.
Fuzzy Logic : Fuzzy logic is an organized and mathematical method of handling inherently imprecise concepts. It is specifically designed to deal with imprecision of facts (fuzzy logic statements). For example, the concept of coldness cannot be expressed through an equation, because it is not quantity like the temperature is. There is no precise cutoff between cold and not so cold. Whether a person is inside or outside the house is imprecise if one stands on the threshold. Is the person slightly inside or outside the house? While quantifying such partial states (xx % inside and yy % outside) yields a fuzzy set membership.

Fuzzy logic is derived from fuzzy set theory dealing with reasoning that is approximate rather than precisely deduced from classical predicate logic. Fuzzy truth represents membership in vaguely defined sets and not randomness like the likelihood of some event or condition. Probability deals with chances of that happening. So fuzzy logic is different in character from probability, and is not a replacement for it. Fuzzy logic and Probability refer to different kinds of uncertainty.

Fuzzy logic is used in high-performance error correction systems to improve information reception (such as over a limited bandwidth communication link affected by data-corrupting noise). Fuzzy logic can be used to control household appliances such as washing machines (which sense load size and detergent concentration and adjust their wash cycles accordingly), refrigerators, rice cookers, cameras focussing, digital image processing (such as edge detection), elevators, Fuzzy logic is used for video game artificial intelligence, language filters on message boards and for filtering out offensive text in chat messages, remote sensing, etc.
.
20 DATA, INFORMATION and KNOWLEDGE –part of the lecture series DESIGN IMPLEMENTATION PROCESSES

























































































{kind=link}